Perspectives of XML in E-Commerce
XML Conformance : The Burden of Proof
XML Entities and their Applications
XML and CSS : Structured Markup with Display Semantics
XML Namespaces : Universal Identification in XML Markup
The Emperor has New Clothes : HTML Recast as an XML Application
You are here: irt.org | Articles | Extensible Markup Language (XML) | XML Euphoria in Perspective [ previous next ]
Published on: Monday 7th February 2000 By: Pankaj Kamthan
"There's an enormous amount of publicity and hype surrounding
XML. There are a lot of statements being made that on face value
... [But] when you look at the explanations ... there's nothing that
would justify those assertions."
- Charles F. Goldfarb, the
inventor of SGML, in
an interview with Web Techniques
From time to time, the computer industry faces crescendos of enthusiasm and wild surges of activity. In the last one and a half years, XML has been heralded as "a true panacea" (for all the Web's problems), "the universal language" (for data on the Web), "a whole new processing paradigm is born", "the second Web revolution" (rise of Java was seen by many as the "first Web revolution"), "a killer application" (that is going to change everything from E-Commerce to object packaging and distribution), and several other metaphors that have bypassed content rating. A revolution brings major upheavals and changes, not all "good", to the society, and does not by itself provide positive solutions. It can create unrealistic public expectations about XML's potential to change the world (and beyond, if the world is not enough).
The commercial aspect of Computer Science and Engineering is particularly inflicted with such upheavals mainly for some form of profit (such as, competitive advantage, potential for higher sales, and so on). The situation in more "stable" areas such as Physics or Mathematics is different. A proposed alternative to Feynman Path Integrals of Quantum Mechanics would go through an exhaustive screening and testing over a period of time by the physics community before it is accepted and considered as an "improvement." Several proofs of the now-famous Fermat's Last Theorem of Number Theory
were carefully studied and discarded prior to arriving to one that was considered "correct" by the mathematical community.
When the XML fog (depending on the weather conditions) settles, sanity (depending on the mental state) returns, and reality surfaces. One is then faced with the problem of separating the fact from the hyperbole. (If not done, it can lead to mental, physical, emotional, monetary and technical problems, of which some of them may be incurable and the process irreversible.) The purpose of this article is to do just that.
The intent here is to objectively view how well XML stands on its own and not to demonstrate the viability of XML in comparison to previous and existing standards (although this line gets blurred at times by necessity). The view expressed in this work should not be taken as lack of enthusiasm for XML and related efforts, but rather that of putting the issues surrounding XML in perspective. It is the hope of this work to provide a basis towards an impartial assessment of XML.
We will use the term data or document in an interspersed fashion only for the purposes of the discussion, and not necessarily in the true sense of the meaning. A basic knowledge of XML syntax is assumed and a preliminary background in XML-related initiatives would be helpful.
This section provides an overview of the history of markup languages. It illustrates that XML (like Rome) was not built in a day and the iterative path to XML "stands on the shoulder of giants."
The (official) birth of markup languages began in late 1960's, when Charles Goldfarb, coined the term "markup language" while working on GML (Generalized Markup Language), an IBM research project, that automated legal documents. This inspired a generic approach to automated documents in general and led to the development of Standard Generalized Markup Language (SGML) in 1970's. SGML is a meta-language, a notation for defining the syntax of markup languages using a Document Type Definition (DTD), which later became an International Organization for Standardization (ISO) standard in 1986. This period also saw the rise of nroff, primarily for UNIX-based systems and commonly used for publishing manual pages. In 1980's, TEX by Donald Knuth, and later LATEX (a macro language based on TEX) by Leslie Lamport, were developed and went on to become the lingua franca for mathematical typesetting.
Presentation is an important aspect of the markup languages. When they first appeared in the 1960's, there were some identifiers for simple purposes like presenting the text in bold or centred like in wordprocessors. As use of markup languages became more widespread during the 1970's and 1980's, it was realizedthat the best way to use markup was by a formal separation of structure and presentation, and macro definitions for formatting were added as a convenient alternative to identifiers. These macros directed output devices (screen, printers, and so on) on how to format the text. For example, the same nroff UNIX man page could be used with a different library of troff macro definitions to generate book-quality or screen-formatted manual pages. LATEX used different "style" files for different purposes such as an article, letter or a book. Markup languages based on SGML used Document Style Semantics and Specification Language (DSSSL), which has a syntax based on the Scheme programming language, for styling purposes.
In 1989, during his invention of the Web, Tim Berners-Lee created the
HyperText Markup Language (HTML), which was an SGML DTD with structure
(\begin ... \end) and semantics (implicitly
presentation-oriented with element names like table)
inspired by the LATEX environment. A
major difference from previous DTDs was a linking mechanism, a prelude
to hypertext, so that the documents could be shared over computer
networks. The ideas for hypertext stemmed from the works of Vannevar
Bush in
"Memex",
and later by Theodor Nelson who coined the term "hypertext"
during his work on the
Xanadu Project.
Initially,HTML did not have any explicit presentational support for
defining the appearance of documents, a task that was provided by
settings in the Web browser.
The early 1990's, there was a rapid growth of the Web, and the use of HTML spread in contexts for which it was not initially designed for. As the demand from the language increased, ad-hoc and at times proprietary extensions to support presentation, interaction (forms), mathematical notation, metadata, multimedia and navigation (frames) were added to it. A major problem that resulted from this endeavour was a mixture of structure and presentation (which were contrary to the original SGML design philosophy). The lack of a clear structure and primarily presentation-oriented semantics made the task of robot indexing and searching imprecise. Furthermore, inspite of the extensions to HTML (which were already making the language monolithic), it could not serve all possible domains of application. In a larger context of Web architecture, this was becoming an obstacle towards usefulness of the Web as a medium for information and communication, and threatened to slow down the development of the Web.
The complexity of SGML and DSSSL prevented their use directly on the Web, and it was realized that a simpler solution that inherited the power of these standards was needed. This led to the formation of Working Group at W3C in 1996, whose efforts eventually led to the birth of XML. In February 1998, XML 1.0 Specification became a W3C Recommendation.
This section outlines some of the basic features of XML, and makes an effort of clearing some of the cloud surrounding them.
A definition is a method of classification. Several "definitions" of XML have been perpetrated: "a format for representing structured documents and data" (in contrast to "XML is a set of conventions for designing text formats for data") or "a system for defining, validating, and sharing document formats" or "a markup language for documents containing structured information (in contrast to "XML is not a single, predefined markup language"). We thus have several loosely stated, conflicting interpretations. Calling XML as a "format" is no better than calling the year 2000 as the beginning of a "new millennium" (it is not, since 0 is not equal to 1) or expressing dates using two-digits as a "bug" (it is not, as decisions based on memory or space optimization issues are not bugs).
Perhaps, a definition is not necessary prerequisite for understanding in this case. (For example, the XML FAQ by Jon Bosak, one of the initiators of XML, does not include any definition for XML. The Annotated XML 1.0 Specification by Tim Bray, one of the editors of the XML Specification, also does not include any definition for XML.) All that is needed is an identification when one (human or machine) comes across syntax enforced by XML. XML is an application profile or restricted form of SGML of in various ways (but not a proper subset in a mathematical sense). It is a meta-language which uses an Extended Backus-Naur Form (EBNF) notation for expressing the syntax rules of a language. (As an analogy, ASCII defines a standard way to map characters to bytes and not an arbitrary set of character strings.) There are several languages that use XML syntax but this should not be taken to imply that they are a subset of XML.
XML is often compared with HTML. It is seen as a "better
HTML," or as
"replacement of HTML"
(which is contradicted by the
XHTML
effort). XML has even been called
"similar to HTML"
or
"like HTML, XML is a set of tags and declarations."
Unfortunately, seeing (the resemblance that it uses "tags"
and attributes) is not always believing and
"looks"
can be deceiving. This comparison is flawed because of its very nature
as: XML is not a language like HTML (it does not have an SGML DTD like
HTML does), XML and HTML are at different "levels" (it is
XML and SGML which are on par), and HTML associates semantics with its
tags (for example, <p> means a paragraph) while XML
does not (for example, <p> in an XML document, in
absence of its "mother-language," could mean anything).
The lessons learnt in the evolution of HTML provide valuable insight in directions of both successes and failures (what could and should not be done). Several functionalities that were "embedded" in HTML over the time, such as, display semantics, linking semantics, and so on, now serve as a prerequisite for various XML-related initiatives.
The title "Extensible Markup Language" was chosen to mean that "the user can choose how to markup the data." However, "extensibility" in XML is often (ambiguously) seen as "extensible because the markup symbols are unlimited and self-defining" (XML is not self-defining as it does not have a pre-determined semantics) or "extensible, which means it can create its own elements" (XML can not create its own elements, as it is not a genetic system that can procure). The question therefore is what exactly is extensible?
Once an XML vocabulary is defined, the "grammar" of the language, in form of an XML DTD or XML Schema, is "fixed" and one can not add new elements without changing it. In this sense, the XML vocabulary is not extensible by itself.
EXAMPLE 1. Consider the following well-formed XML fragment:
<?xml version="1.0" encoding="ISO-8859-1"?> <em> <to>foo@somewhere.com</to> <fr>bar@somewhereelse.com</fr> <su>Did you know?</su> <me>The quick <co>brown</co> <an>fox</an> jumped over the lazy <an>dog></an>?</me> </em>
to which we add the si element for sender's signature:
<?xml version="1.0" encoding="ISO-8859-1"?> <em> <to>foo@somewhere.com</to> <fr>bar@somewhereelse.com</fr> <su>Did you know?</su> <me>The quick <co>brown</co> <an>fox</an> jumped over the lazy <an>dog></an>?</me> <si>John Smith, Yoyodyne Inc., Nexus-6</si> </em>
which gives us another well-formed XML fragment. So, now that XML allows documents using XML-syntax to be well-formed, one can make any arbitrary extensions. But is this extensibility any useful? A well-formed XML document, in absence of a DTD, still implicitly implies an XML DTD (which, if needed, can be generated). Modifying the document, then means that the underlying DTD has also been implicitly modified. (For instance, XML DTD's generated for the two fragments above will be different.)
It may be more useful to see that the "extensibility" of XML comes in other ways: explicit interoperation of XML vocabularies, such as, by use of the OpenMath encoding CD's in Mathematical Markup Language (MathML), use of the animation element in Scalable Vector Graphics (SVG) using Synchronized Multimedia Integration Language (SMIL) properties, use of Cascading Style Sheets (CSS) style properties in many XML vocabularies; by use of XML Namespaces; by modularization (such as Modularization of XHTML); and by use of XML Schemas.
This section evaluates characteristics inherent to the nature of XML.
XML is a data representation with the characteristics of a document. Therefore, one can first parse an XML file to extract the data and then process it (machine-centric use), or one can present the file as a document by using style sheets (human-centric use). This helps us to do both things in the same application at the same time.
EXAMPLE 2. The blurred distinction whether an XML file is data or document has its limitations if the view is improperly propagated. For example, drawing a basic primitive in SVG, such as a "unit" circle is straightforward:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE svg PUBLIC "-//W3C//DTD SVG December 1999//EN" "http://www.w3.org/Graphics/SVG/svg-19991203.dtd"> <svg width="400" height="400" > <title>A Simple Circle</title> <g><circle cx="10" cy="10" r="100" style="fill: white; stroke: black" /></g> </svg>
However, graphics is more than just circles or rectangles. The figure below represents a simple technical drawing for a schematic of an intranet in an educational setting:
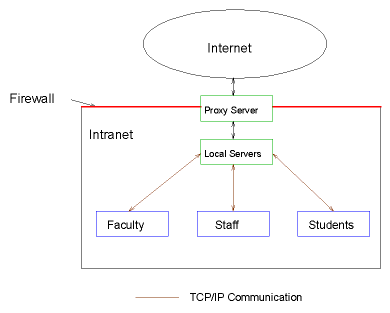
The corresponding SVG source file (11K) is available (though not optimized for delivery). If there is any undesirable aspect of the drawing that can not be improved using the software which generated (exported) it, the only way of going about it is the examination of the markup itself. This is quite possible if the file is purely "document-centric" but nontrivial, trial-and-error exercise, if it is not.
XML was (as opposed to HTML) designed primarily to be machine-processable; XML is text, but isn't meant to be read. One indication of this is that XML-related initiatives belong to the W3C Architecture Domain (whereas HTML-related efforts are part of the User-Interface Domain).
An XML document can be viewed as a hierarchical tree of objects. This view has been used in defining the XML DOM. However, these objects are static; they do not have support for tasks such as secure transactions or session management. Such characteristics often taken for granted from objects in various object-oriented languages. It is expected that XML-CORBA synergy could bring an interoperable solution.
To manipulate these "XML objects," some sort of programming capability is needed. Several solutions have emerged, depending on server-side (Tcl, Perl for scripting; C++, Java for programming) and/or client-side (ECMAScript) interactions using "object serialization" (object-text-object conversion). Unfortunately, this "bias towards serialization" also make XML unsuitable for general-purpose data modelling.
Idempotency is both XML's strength and its weakness. Idempotency means that the effect of doing something multiple times is the same as the effect of doing it once. For example, if A is a nxn (square) matrix, and I is an nxn identity matrix, then the matrix product A*I*...*I = A*I (= A), always.
If XML-based idempotent information such as an e-mail message (for human consumption) is distributed, sending the same message multiple times would not have any real damaging effect. However, sending an online order (for machine consumption) of the same list of products multiple times does make a difference. Therefore, in situations of entirely machine-to-machine communication and interaction with no human intervention, use of XML needs to be reevaluated. Solutions may require use of some form of "checkposts" (or "state persistence" as currently done in the human-to-machine interface of a Web browser using cookies).
XML text-format has a few disadvantages with respect to binary representations, all of which are inevitable consequences of XML's flexibility: size and performance. XML content usually occupies more space than binary representations counterparts, and as a result, take more disk space and may also take more time when transmitting over a network. It takes more work to read large XML documents than binary formats as the tags must be read and processed, and information such as numbers will have to be converted from its textual form to the binary form, when required by the application. Also, be definition, XML documents contains much duplication of markup. It is not surprising that embedded markup can be considered harmful.
As an example, the second option in each of the following test cases led to verbose file sizes: SVG DTD vs. corresponding XML Schema, GIF vs. SVG for several nontrivial images, TEX markup vs. MathML markup for several both trivial and nontrivial mathematical objects (such as, equations, expressions, matrices).
Fortunately, with disk space getting cheaper, network bandwidth getting cheaper/faster, and CPU's getting cheaper/faster, performance will become lesser of an issue. In addition, HTTP/1.1 can compress data on the fly, thus saving bandwith as effectively as a binary format. XMLZip provides another solution to this issue. When utilizing the XML DOM API, XML files can be compressed based on the node level in the XML document. On the client-side the XML file can be selected and uncompressed according to the specific node the user is referencing, rather than uncompressing the entire document.
XML does not implicitly imply any semantics. The freedom of XML comes at a price. This lack of any predetermined semantics makes XML documents no more "self-describing" than a database schema. XML DTDs specify the relative positioning of its components (elements, attributes, entities) but not what an XML tag means. The terms used in an XML DTD are derived from a natural language. The "meaning" assigned to the terms is based on intuition by assuming that the developer of the DTD used the words in the way we would expect. The intuitiveness has its limitations within the use of same language in a single culture, and the situation worsens across languages and cultures. Without sufficient documentation, the element <em> in Example 1 above could be interpreted as either "e-mail" or "emphasis" or something else; similarly, <fr> could imply "from" or a country code. Still, flexibility of XML syntax does represent a major improvement over that of HTML.
This problem will be somewhat circumvented with the adoption of XML Schema and standardization of such "terms" to be used in XML vocabularies. In addition, widespread use of assertions based on Resource Description Framework (RDF) will also provide clarity reducing the possibility of ambiguous interpretations with a move towards a Semantic Web.
The design goals for XML are:
The Annotated XML 1.0 Specification provides annotations on each of these goals. As it also points out, some of these goals have yet to be completely realized.
In 1997, before XML became a W3C Recommendation, several XML parsers with their own proprietary APIs came into existence, one of the earliest being the implementation in the JUMBO XML/CML Browser browser that supports the Chemical Markup Language (CML). To standardize this effort, a Simple API for XML (SAX) was developed. SAX is a standard interface for event-based XML parsing, developed collaboratively by the members of the XML-DEV mailing list. SAX 1.0 was announced in May 1998 and is for both commercial and non-commercial use (with version 2.0 under development). SAX implementations are available in several languages, including C++, Java and Python. Another option for parsing XML documents is provided by using the "object model" such as the XML Document Object Model (DOM) which provides APIs that let you create/manipulate/delete the nodes. This helps one to create a DOM from an in-memory object tree. However, the DOM Level 1 Specification does not specify how to convert XML from an existing file into a DOM, and so this has been implemented differently in different XML parsers, which makes the transition cumbersome. Though XML parser development has reached a level of maturity and stability, they can be slow because they need to read the entire file to find out what it contains, and they consume considerable memory because all the parts of the file required needs to be loaded at the beginning.
The situation is a lot less glorified outside the parser arena and there are several obstacles that still remain from an XML (software) developer viewpoint. XML evolution mimics a shooting range with moving targets. These targets have only increased in time in a chain reaction of events, where initiatives have split, one of most notorious being Extensible Style Sheet Language (XSL).
It is expected that efforts of modularization of XML vocabularies, with modules available for specific device (such as a handheld or a cellular phone) profiles, will assist in the development as then one need only to support the part of the language that is deemed "fit" for a particular device.
XML authoring support is in a good shape as several freeware/shareware/commercial generic authoring environments are available that are XML and DTD syntax-sensitive. Authoring/rendering issues associated with specific XML vocabularies are discussed in the section XML Case Studies.
Even though eventual rendering is user-centric, authors are not (or should not be) immune to it. The process of authoring and rendering go hand in hand; as a principle of "good" authoring, one must render the documents during the testing phase of authoring.
The current saga of authoring/rendering is a discouraging reminder of the situation that persists in the world of HTML, CSS and DOM (Level 0 and 1) implementations in the form of JavaScript and VBScript. A combination of all of these technologies is popularly known as Dynamic HTML (DHTML). Even after years of effort, there does not exist a browser that implements DHTML completely on any platform, or even degrades gracefully. This is inspite of the fact that the author may be following the respective specifications. The result is a "renderer-oriented" authoring, rather the other way round. This may work well in an "encapsulated" environment of say an intranet but does not scale at the level of the Internet as there is no guaranteed way of predetermining the computing environment at the delivery-end.
If the situation in DHTML is far from satisfactory, the transition towards Dynamic XML (DXML), will not make the problems vanish, and might make it even worse. XML documents can be created with arbitrary complexity with the help of XML Namespaces, where elements (and attributes) from different XML vocabularies can be mixed without the potential danger of an ambiguity. The question then is: How well will the processors (for example, renderers) support an XML vocabulary, and to what extent? For example, a renderer that claims to support MathML Presentation Markup and SVG may only support a partial list of MathML Entities and an incomplete list of SVG style attributes. So, even if the author creates a document conforming to the specifications, there is no apriori guarantee whether the document will be rendered completely, partially, or with extraneous interpretations of the renderer. The term "generic XML browser" is more a marketing rhetoric than reality and XML support in current browsers such as Microsoft Internet Explorer 5.x is extremely limited.
Wherever there is a format, is there XML?
There has been a lot of "*-to-XML"-type movement with questions such as: Should we replace a format * by XML? XML does not provide a guideline for a "suitability." Not every text format lends itself automatically to be expressed in XML, and even if it does, there may be several reasons for not doing so. For example, for floating-point numbers, corresponding XML files would be relatively much larger than the one written in native floating-point format, and writing an XML parser for processing such files will be relatively time-consuming.
There are several questions that need to be answered when considering a transition to XML from an existing platform based on HTML: What happens to the existing plethora of HTML documents? (This can be answered somewhat with the XHTML initiative.) How, at what cost (time, effort, money, personnel), and if at all possible, could the transition be made to be incorporated into the XML world? What will be the desired XML vocabulary-of-choice? Will "XML-enabled" search engines be backward compatible to be able to search (malformed) HTML documents?
One of the design goals for XML, says that "XML documents shall be easy to create." Since complex XML documents may be easy to create for a machine (program), but may be difficult for a human, it remains unclear whether this goal has been (or can be) attained. In contrast to this, it is the flexibility of XML (data/document views) that has made it complicated and less useful for data-centric applications both on and off the Web. This is the belief behind the movement for a Simple Markup Language (SML), which emphasizes the data view as opposed to the document view. The problem with this approach is that different users may want different things simplified. Actually, DTD-less XML applications are already examples of a "simplified" use of XML. The question is not whether an initiative such as SML is a solution, but just the fact that it is being considered with an entire mailing list (SML-DEV) and forum dedicated to it, raises several questions regarding the state of XML.
Another goal states that it should "be easy to write programs which process XML documents." One also continues to see statements such as "the simplicity of XML reduces the cost of training programmers and application maintenance." Simplicity should not mean to imply easy, and vice versa. (The case of Fermat's Last Theorem is an example.) Also, simplicity may even imply "vagueness." This open-to-interpretation nature of XML has led to various ad hoc implementations, leading to more complexity rather than simplicity. This issue was realized and XML Information Set that describes an abstract data set containing the information available from an XML document and Canonical XML that describes a subset of the information contained in an XML document, are two efforts which together will "simplify" the procedure of processing an XML document (and as a bonus, also lend to more efficient processing).
The goal of keeping XML as "simple" as possible (but not simpler to the point of reductio ad absurdum, that is, logic proves otherwise) and, the question whether Goldilocks find XML to be tasteful, remains to be seen.
This section discusses the state of applications based on XML.
The Extensible Markup Language (XML) 1.0 Specification became a W3C Recommendation in 1998. The XML "family" of technologies has grown many-fold since then. The W3C initiatives in XML can be placed into the following categories (the list is only to serve as an example and is not exhaustive):
XML was enthusiastically embraced in many application domains because there are a lot of applications that need to store data intended for human use, but which it will be useful to manipulate by machines. This led to several XML applications and XML vocabularies, some of which are academic while others are part of cross-domain and multi-disciplinary enterprises. Though some of these lack maturity and technical quality, many hold promise, and reflect strong commitment to open standards initiatives. Not all the efforts form a "standard." Furthermore, not all implementations are complete and are of the type "we pick-and-choose and let the author loose," resulting in an apparent danger of "islands of incompatible information."
Inception of technologies, such as XML, usually takes place with the identification of problems and the realization that the then-existent solution(s) to problem(s) are unsatisfactory in one way or the other. The XML Specification states:
The utility of XML as a meta-language, however, has surpassed this intent of the language designers. This, depending on the data to be modelled, can have both positive and negative repurcussions. Several compelling applications have appeared as a result. There is, however, no receipe for "warning" as data modeling is science, as well as, an art. So, over-expectations followed by hasty actions in absence of reasoning, can lead to catastrophies. In the real-world, using a microwave to cook an entire gourmet feast for a royal banquet, or using a Concorde for intracity transit, can both yield unexpected and undesired results. XML is no exception, and applications of XML to scenarios external to those problem domains may not lead to positive results. These should not be seen directly as limitations of XML itself, as it wasn't designed to solve those problems in the first place. The evolution of HTML serves as an example.
In the end, XML isn't always the best solution, but it is always worth considering, particularly if the underlying data has some structure. The advantage of choosing XML as the basis is that one can rely on growing community of experts and wide availability of Open Source software.
In this section, we will consider the cases of SMIL and Electronic Commerce (E-Commerce), in detail.
SMIL was developed to support interactive synchronized multimedia distributed on the Web. According to CWI, SMIL provides Web users with "easily-defined basic timing relationships, fine-tuned synchronization, spatial layout, direct inclusion of non-text and non-image media, hyperlink support for time-based media, adaptiveness to varying user and system characteristics."
There are several obstacles for deployment from an author's viewpoint. Unlike MathML or SVG, SMIL is more like a "manager" language which "synchronizes" existing content; it does not create or generate the content. The burden to create content separately still rests on the author. Creating media files, particularly videos, can be time consuming and expensive. The current development environment is primarily Windows-based, and there is a lack of Macinctosh-based (a widely-used platform in multimedia arena, particularly in training) authoring tools. Media is about integrating technology with creativity and, for historical reasons, most creators still use Macintosh as their platform of choice. Lack of software for Macintosh could well be one of the reasons for the slow adoption of SMIL on the Web. For use of SMIL for slideshow presentations, there are various competing technologies such as Microsoft PowerPoint, Java applets and Macromedia Flash, which have both superior authoring and rendering support than SMIL. Several advantages that SMIL offers being based on XML syntax thus get overshadowed. So, assertions in context of SMIL, such as "producing audio-visual presentations for the Web is easy" or "anyone can make multimedia for the Web" implying that now everybody will become a movie producer are over-optimistic and merely theoretical. Also, generalizations such as "death of the TV" are contrary to the "official" announcement that SMIL Boston has been designed (via module profiles) for integrating multimedia objects into digital television broadcasts.
For a wide-use of any technology, it also has to be widely accessible. There are several obstacles from a user's viewpoint, particularly performance. Even though SMIL files presenting complex phenomena may not be large themselves, the media content they synchronize can be large, and overall delivery on the Web can be performance intensive. Not everybody is currently on a T1 connection, and so even the use of streaming media results in "buffering" the video content, thereby presenting it poorly in "slow motion." Downloading the file when available is an occassional possibility, but that can be prohibitive for large file sizes, and even then, provides no distinctive advantage of the Web over a desktop. FTP access to files predates the Web. Useful variety of available examples are rare and mostly focus on advertising a company or its product which do not directly benefit the user.
E-Commerce has tremendously benefited from the Web, and conversely, is a major factor in the evolution of the Web. E-Commerce on the Web has grown dramatically in the last few years and recent surveys predict that this trend will continue both in the area of Business-to-Consumer (B2C) and Business-to-Business (B2B) E-Commerce.
The integration of XML in all arenas of E-Commerce has several problems ranging from technical to social to political, eventually leading to a lack of standardization in several phases of business processes. From the point of view of legacy content, there are questions regarding how to make the transition or even to make one at all. If the transition is to be made, what should be the vocabulary-of-choice for converting traditional Electronic Data Interchange (EDI) messages (representing, for example, invoices and purchase orders), or data in relational database tables (representing, for example, product information)? The arguments are for and against this trend. We will use EDI as an example. In a setting of supply-chain management, use of XML as a replacement of EDI warrants serious consideration for several reasons:
Thus, enticing slogans such as "save millions with XML-EDI integration" or assertions such as "XML is the closest thing to a Holy Grail of E-Commerce data interchange" and "XML And E-Commerce: A Match Made In Heaven" that have a religious flavour, should be taken with a grain of salt. Use of XML in E-Commerce "gold rush" can be promising, as demontrated by a variety of scenarios, but can lead to various pitfalls if lessons from the past failures are not learnt.
XML : Reevaluation? Definitely. Breakthrough? Possibly. Evolution? Hopefully. Silver Bullet? Hardly.
XML is an important step in the evolution of the Web architecture. It has reminded us that a fixed-tag presentation-oriented language is not sufficient for various software applications and hardware devices, and the days of "one-size-fits-all" solutions are a passé. While travelling "downward" on the "Web mountain road," XML represents retracing back and seeing the problems from a higher (SGML) level. The breakthrough is thus in form of a novel way of thinking of traditional problems. Whether this is a major step forward is yet to be seen and determined.
Embracing a new technology implies replacing applications based on existing technology and/or creating entirely new applications. Some evolutions are hard to distinguish from revolutions. If XML is a revolution, should we immediately (and blindly) embrace it? If XML is just a media hype created "by the people, for the people," should we ignore it as a passing phenomenon? The XML applications demonstrate that neither extreme is true. A balance in deployment based on careful study, reflection and experimentation, is therefore necessary.
In conclusion, the design of XML-related efforts marks only the beginning, and the task of putting XML to work is far from over. The issues raised here are simply a reminder that several questions remain unanswered and new twists and turns may lie on the road ahead.
Perspectives of XML in E-Commerce
XML Conformance : The Burden of Proof
XML Entities and their Applications
XML and CSS : Structured Markup with Display Semantics
XML Namespaces : Universal Identification in XML Markup
The Emperor has New Clothes : HTML Recast as an XML Application
{kind=link}