The State of MathML : Mathematically Speaking (and Stuttering)
XML Namespaces : Universal Identification in XML Markup
You are here: irt.org | Articles | Extensible Markup Language (XML) | The Emperor has New Clothes : HTML Recast as an XML Application [ previous next ]
Published on: Sunday 30th January 2000 By: Pankaj Kamthan
After a period of dormancy, a relatively silent but significant change has taken place that will redefine the way HTML is currently served, received and processed. This evolution has been in the direction of XML (Extensible Markup Language), that in the last one year has emerged as a powerful meta-markup language for the Web.
Since the majority of information on the Web still exists in the form of HTML, there is a dire need of a mechanism for a transition from HTML to XML that is as transparent as possible. XHTML is intended to fill this gap, which is the subject of this article. (The term XHTML should not be confused with the HTML editor Xhtml.) It is intended to be used as a language for content that is both XML-conforming and, if some simple guidelines are followed, operates in HTML 4 conforming user agents.
There are several questions that an author needs to ask him/herself:
In what follows, we assume that the reader is already familiar with HTML 4. Some knowledge of XML can also be useful.
The evolution of markup languages for the Web went through two major milestones: development of HTML, which built the Web architecture, and XML, which is poised to consolidate the same.
SGML (Standard Generalized Markup Language) is a meta-language for describing markup languages, particularly those used in electronic document exchange, document management, and document publishing. It is both feature-rich and flexible. This flexibility, however, comes with a level of complexity that has inhibited its adoption on the Web.
HTML is an SGML application, and is widely regarded as the standard publishing language of the Web. HTML was originally conceived as a language for the exchange of scientific and technical documents, suitable for use by non-document specialists. HTML addressed the problem of SGML complexity by specifying a small set of structural and semantic tags suitable for authoring relatively simple documents. In addition to simplifying the document structure, HTML added support for hypertext. Later, multimedia capabilities were added.
In a remarkably short time span, HTML became very popular and rapidly outgrew its original purpose. Since its inception, HTML has gone through several stages of evolution, both standard and proprietary, to adapt it to a very diverse and international community wishing to make information available on the Web. This evolution has led to interoperability problems for documents across different user agents. With the rapidly proliferation of the heterogeneity of both software and platforms, the situation has worsened.
The current HTML standard, HTML 4.0 Specification, was announced as a W3C Recommendation on December 18, 1997 and revised on April 24, 1998. It has recently been revised to HTML 4.01 Specification with minor changes. By "HTML 4," we will mean HTML 4.01 unless stated otherwise.
XML was conceived as a means of regaining the power and flexibility of SGML. While retaining all of SGML's commonly used and beneficial features, XML removes many of the more complex features of SGML. XML 1.0 Specification, was announced as a W3C Recommendation on February 10, 1998. As the acceptance of XML grew, it was realized that there is was very large base of Web documents, transition of which to XML poses a major issue. The past few years also saw a rise of access to the Web using a variety of devices with varying computing power. The questions in the development of the XHTML were: how to design the next generation language for Web documents without obsoleting the existing content on the Web, and how to create a markup language that supports device-independence. The result is XHTML.
XHTML is a family of current and future document types and modules that reproduce, subset, and extend HTML 4. XHTML family document types are XML based, and ultimately are designed to work in conjunction with XML-based user agents. XHTML 1.0 is the first document type in the XHTML family. It is a reformulation of the three HTML 4 document types as applications of XML 1.0. XHTML 1.0 was announced as a W3C Recommendation on January 26, 2000.
XHTML 1.0 connects the present Web to the future Web
-Tim Berners-Lee, in XHTML 1.0 Press Release
The XHTML 1.0 (and XHTML family, in general) offers several advantages to an author:
<dt> tag might be
terminated by </dt>, by another <dt>, by a <dd>,
or by a </dl>, or by something else. This makes processing software
development difficult as one has to "predict" all possibilities and include
appropriate response. Since XHTML 1.0 is based on XML, every XHTML 1.0 document must be
well-formed, thus excluding "unpredictable" scenarios.In our context, a DTD is a collection of XML declarations that, as a collection, defines the legal structure, elements, and attributes that are available for use in a document that complies to the DTD. Each DTD can be recognized by a unique label called a formal public identifier (FPI). It is a definition of what qualifies as legal syntax in XHTML 1.0. The semantics of the XHTML 1.0 elements and their attributes are as defined by the HTML 4 Specification.
XHTML 1.0 specifies three XML document types that correspond to the three HTML 4 DTDs: Strict, Transitional, and Frameset.
XHTML 1.0 Strict.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
You should use this when you want presentational markup to be seperated from the structure of the document. Cascading Style Sheets (CSS) can be used for the purpose of presentation.
XHTML 1.0 Transitional.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
You should use this when presentational markup needs to be embedded in the document (for example, to support browsers that are not CSS-compliant).
XHTML 1.0 Frameset.
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Frameset//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-frameset.dtd">
You should use this when you want to have a HTML Frames-based document.
The system identifier may be changed to reflect local system conventions. These DTDs approximate the HTML 4 DTDs, though, a DTD for XHTML 1.0 is more restrictive than the DTD for HTML since XML is more restrictive than SGML.
The XHTML entity sets are the same as for HTML 4, but have been modified to be valid XML 1.0 entity declarations. The modified set includes Latin-1 characters, special characters and symbols.
There are cases where different XML documents may have same element or attribute names.
Combining element names from different documents into one document then becomes an issue.
For example, a title element may mean the title of a person in one
document and of a book in another. Including the information from both documents into a
single document will lead to a conflict.
XML Namespaces provide a method for qualifying element and attribute names used in XML documents by associating them with namespaces which are identified by URI references. This allows element names from different documents to be combined in one document without conflict in cases where names happen to be identical. It uses qualified names to prevent potential conflicts between identically named XML elements, by associating a prefix which identifies an intended namespace with an URI.
The XHTML namespace is given to be http://www.w3.org/1999/xhtml.
A strictly conforming XHTML 1.0 document is a document restricted to tags and attributes from the XHTML 1.0 namespace. Such a document must meet all of the following criteria:
html.xmlns attribute. Example 1. The following is an example of a minimal XHTML 1.0 document:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>The Minimal XHTML 1.0 Document</title>
</head>
<body>
<p>This is a minimal XHTML 1.0 document.</p>
</body>
</html>
The XHTML 1.0 namespace may be used with other XML namespaces. Though such documents are well-formed with respect to XML syntax, they are not strictly conforming XHTML 1.0 documents.
Example 2. Non-XHTML Namespace in XHTML 1.0 Document. The following example shows the way in which XHTML 1.0 could be used in conjunction with the MathML 1.01 Specification:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd">
<html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en">
<head>
<title>A MathML Example</title>
</head>
<body>
<p>The following is an example of MathML Content markup:</p>
<math xmlns="http://www.w3.org/1998/Math/MathML">
<apply><root/><ci>x</ci></apply>
</math>
</body>
</html>
Example 3. XHTML 1.0 Namespace in a Non-XHTML Namespace Document. SVG provides extensibility by inclusion of elements from foreign namespaces. The following example shows the way in which XHTML 1.0 content could be embedded in a SVG document:
<?xml version="1.0" standalone="yes"?>
<svg width="500" height="400" xmlns="http://www.w3.org/Graphics/SVG/SVG-20000802.dtd">
<defs>
<html:html xmlns:html="http://www.w3.org/Profiles/xhtml1-transitional">
<html:head>
<html:title>Sales By Department</html:title>
</html:head>
<html:body>
<html:table align="center" cellpadding="5" border="1">
<html:tr><html:th>Department</html:th><html:th>Revenue</html:th><html:th>Profit</html:th></html:tr>
<html:tr><html:td>A</html:td><html:td>100</html:td><html:td>5</html:td></html:tr>
<html:tr><html:td>B</html:td><html:td>200</html:td><html:td>15</html:td></html:tr>
</html:table>
</html:body>
</html:html>
</defs>
<desc>Sales By Department</desc>
<g style="stroke: #000000">
<line x1="10" x2="150" y1="150" y2="150" style="stroke: #000080"/>
<line x1="10" x2="10" y1="10" y2="150" style="stroke: #000080"/>
<text x="10" y="10" style="font-size:14; font-family: Tahoma">Profit</text>
<text x="10" y="165" style="font-size:14; font-family: Tahoma">0</text>
<text x="150" y="165" style="font-size:14; font-family: Tahoma">Department</text>
<rect style="fill: blue; stroke: red" x="40" y="125" width="20" height="25"/>
<text x="40" y="165" style="font-size:12; font-family: Tahoma">Products</text>
<text x="40" y="120" style="font-size:12; font-family: Tahoma">5</text>
<rect style="fill: blue; stroke: red" x="90" y="75" width="20" height="75"/>
<text x="90" y="165" style="font-size:12; font-family: Tahoma">Services</text>
<text x="90" y="70" style="font-size:12; font-family: Tahoma">15</text>
</g>
</svg>
It is preferable to separate the style attributes in a CSS style sheet.
This section outlines the differences between HTML and XHTML 1.0 syntax. Most of the differences stem from the fact that XHTML 1.0 is an XML application, and certain practices that are legal in SGML-based HTML 4 need to be revised. Wherever relevant, we will include suggestions according to the HTML Compatibility Guidelines on ensuring backward compatibility.
Internet Media Type
XHTML 1.0 documents which follow the HTML Compatibility Guidelines may be labeled with the Internet Media Type "text/html", as they are backward compatible with most HTML browsers. The general recommended MIME labeling for XML-based applications has yet to be resolved.
Processing Instructions
The XML declaration, such as, <?xml version="1.0"
encoding="UTF-8"?> is not required in all XHTML 1.0
documents. Such a declaration is, however, required when the (Unicode-based)
character encoding of the document is other than the default UTF-8 or UTF-16.
Therefore, it is a good practice to use XML declarations such as the above in all XHTML
1.0 documents.
DOCTYPE Declaration
The purpose of the DOCTYPE declaration is to declare that the document
adheres to a specified DTD. An XHTML 1.0 document must have a DOCTYPE
declaration just before the <html> tag and must reference one of the
three XHTML 1.0 DTDs.
Element Language
The language of elements is specifying by using both the lang and
xml:lang attributes. The value of the xml:lang attribute takes
precedence.
Root Element
The root element of an XHTML 1.0 document ("html") must
designate a XHTML 1.0 namespace.
Well-Formedness
A document is well-formed when it is structured according to the rules defined in Section 2.1 of the XML 1.0 Specification. An XHTML 1.0 document must be well-formed. Basically, this means that elements, delimited by their start and end tags, are nested properly within one another. Although overlapping is illegal in SGML, it is widely tolerated in existing browsers. Example:
| HTML | XHTML |
|---|---|
<p>This is <b>bold.</p></b> |
<p>This is <b>bold.</b></p> |
Element and Attribute Names
Since XML is case-sensitive, all HTML element and attribute names must be in lowercase. Example:
| HTML | XHTML |
|---|---|
<BODY BGCOLOR="#ffffff"> |
<body bgcolor="#ffffff"> |
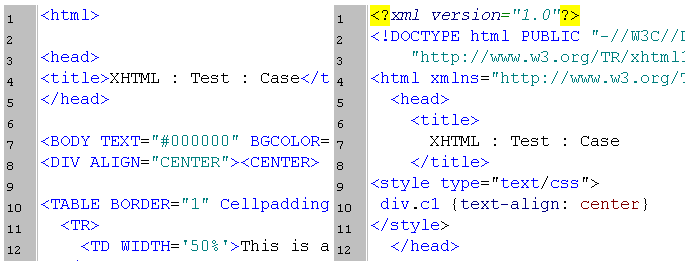
In an effort towards migrating existing documents in HTML to XHTML 1.0, you can use HTML-Kit to change the case of element and attribute names in a document. Here is an example document before and after the case change and conversion from HTML to XHTML 1.0.
Pattern matching capabilities of Perl can also be used to change case. This solution will have the advantage of doing that for an entire set of HTML documents and will be portable across platforms which have Perl installed on them. However, a generic solution which changes the case of element and attribute names while ignoring attribute values, may be nontrivial.
Attribute Values
User-defined attribute values, however, can be in any case. For example, the
"#ffffff" above can also be written as "#FFFFFF."
The above is only for illustration; HTML 4.01 discourages use of style
attributes. It is suggested that all presentation be carried out via
CSS.
Empty Elements
Empty elements must either have an end tag or the start tag must end
with />. This is also sometimes called a self-terminating
element. Example:
| HTML | XHTML |
|---|---|
<hr> |
<hr /> or <hr></hr> |
Note the space between the element text and the />. <hr />,
known as the minimized tag syntax, is preferred over <hr></hr>
as the latter gives unexpected results on some user agents.
Non-Empty Elements
An non-empty element does not have (as designated by the DTD) an EMPTY in its content model. (The term "empty" is being used in a set-theoretic sense.) Due to its SGML legacy, the start and end tags for elements in HTML can (depending on the case) either be required or be optional. For example, for the "head" element, both the start and end tags are optional, for the "p" element the end tag is optional, and for the "title" element, both the start and end tags are required. This is not possible in XML. In XML, both the start and end tags are required for all non-empty elements. XHTML 1.0 does not provide such liberty of choice. Both start and end tags for elements are required. Therefore, all elements other than those declared as EMPTY in the DTD must have an end tag. (The exception to this rule are empty elements, which are treated differently as indicated above.) Example:
| HTML | XHTML |
|---|---|
<p>A paragraph |
<p>A paragraph</p> |
One important implication of this is that it increases the size of the document, which in turn has an affect on the delivery time.
There is a difference between an empty element and an empty instance
of an element (non-empty element). Therefore, non-empty elements with
empty content should not use the minimized form. For example, an empty
paragraph (a paragraph with no content to encapsulate) should be
represented as <p&t;</p> (and not <p />).
Attribute Values
All attribute values, including those which appear to be numeric, must be quoted (in single or double quotes). Example:
| HTML | XHTML |
|---|---|
<table border=1> |
<table border="1"> |
This would need some adjustment in practices of dynamically generating HTML.
If double quotes are used, for example, in case of Perl:
print "<table border=1>\n"; will need to be changed to
print "<table border=\"1\">\n"; with the quotes being
escaped.
Attribute Minimization
An attribute is said to be minimized when there is only one value for it. For example,
in the form element <input type="checkbox" ... checked>, the
attribute checked has been minimized. XML does not support attribute
minimization. In XHTML 1.0, attribute-value pairs cannot be minimized and must be written
in full (as if they had values). Example:
| HTML | XHTML |
|---|---|
<input type="checkbox" ... checked> |
<input type="checkbox" ... checked="checked" /> |
Elements with id and name Attributes
HTML 4.0 defined the name attribute for certain elements (a, applet,
frame, iframe, img, and map) and also
introduced the id attribute. Both of these attributes are designed to be used
as fragment identifiers. In XHTML 1.0, the name attribute of these
elements is formally deprecated. XHTML 1.0 documents must use the id
attribute when defining fragment identifiers, even on elements that previously had a name
attribute.
When serving XHTML 1.0 documents as media type text/html, see the HTML Compatibility Guidelines for
information on ensuring backward compatibility.
White Spaces in Attribute Values
White space characters, such as a line break, are handled differently by different user agents. When white space is used in attribute values, user agents strip leading and trailing white space and map sequences of (one or more) white space characters to the ASCII space character inter-word space. Therefore, you should avoid line breaks and multiple white space characters within attribute values.
Script and Style elements
The main purpose for character data (CDATA) sections is to ignore
characters that would otherwise be regarded as markup. The only delimiter that is
recognized in a CDATA is the string "]]>" which
ends the CDATA section.
In XHTML 1.0, the script and style elements are declared as having parsed
character data (#PCDATA) content. As a result, and contrary to the possible
intended purpose, < will be treated as the start of markup. An
entity such as < will be recognized as an entity reference by
the XML processor to be <. Use of & and ]]>
within script and style sheets will also create confusion. Therefore, the content of the
script or style element should be wrapped within a CDATA marked section to
avoid any unintended interpretation. Example:
| HTML | XHTML |
|---|---|
<script type="text/javascript"> ... script content ... </script> |
<script type="text/javascript"> <![CDATA[ ... script content ... ]]> </script> |
This only applies when you're including code inside these elements. This does
not apply in cases of external references to scripts and style sheets, for
example, <script type="text/javascript"
src="foo.js"></script> and <link
rel="stylesheet" href="bar.css" type="text/css" />
. Therefore, as an alternative to using the CDATA wrapper, you can use
external scripts and style sheets.
Form Elements
The isindex element is deprecated in favour of the input
element. If used at all, only one isindex element should be included
in the document head.
Entity Sets
The XHTML 1.0 entity sets are the same as for HTML 4, but have been modified to be valid XML 1.0 entity declarations.
SGML Exclusions
SGML gives the author of a DTD the ability to exclude specific elements from being contained within an element. Such prohibitions or exclusions are not possible in XML. The following XHTML 1.0 elements have prohibitions on which elements they can contain:
a cannot contain other a elements.pre cannot contain the img, object, big,
small, sub, or sup elements.button cannot contain the input, select, textarea,
label, button, form, fieldset, iframe
or isindex elements.label cannot contain other label elements.form cannot contain other form elements.Migration of content from HTML to XHTML 1.0 offers various benefits:
text/html will continue to operate
(as well or even better than it did before) in existing HTML 4-conforming user agents, as
well as in new XHTML 1.0 conforming user agents. XHTML 1.0 documents with appropriate
style sheet support will operate just as well in XML-based user agents as they do in
HTML-based user agents.The HTML to XHTML 1.0 transition, though simple, deserves a careful consideration as it involves several issues:
One approach towards the transition of (existing legacy) HTML documents to XML is to translate them to XHTML. As seen in the section on HTML vs. XHTML Syntax, this can require quite a few changes (particularly, if the original document was non-HTML 4 conforming). This section looks at some tools to make make that task easier. One such tool is HTML Tidy.
To convert documents from HTML to XHTML 1.0, you can use HTML Tidy, a freely available utility available for a variety of platforms. It also cleans up markup errors, and reformats the markup for legibility and maintenance.
You can use Tidy by the following on the command line:
tidy [[options] filename]*
By default, input and output are directed to stdin and stdout respectively, and errors to stderr. This can be changed by using one or more of the various useful options that Tidy offers, which can be seen by:
tidy -help
A selected list of some commonly used options is given in the table below; for an entire list, you can refer to the official documentation:
| HTML Tidy Command Line Option | Function |
|---|---|
-help |
List command line options |
-config file |
Read config file |
-m |
Modify original files |
-f file |
Write errors to file |
-asxml |
Convert HTML to XML |
-xml |
Use this when input is in XML |
The -m option should be used with care as it modifies the original
file. The -f option can be used to direct the errors to a file, which makes
it easier to review them later. For instance:
tidy -m -f error.txt file.html
runs tidy on the file file.html, updating it and writes the error messages
to the file error.txt.
The most convenient way to configure Tidy is to use a configuration file. If you have a config file named config.txt, you can instruct Tidy to use it via the command line option -config config.txt, as in:
tidy -config config.txt file1.html file2.html
There are again various options that are supported. A list of some commonly used options is given in the Appendix. Here is a sample configuration file:
// A sample configuration file for HTML Tidy indent: auto wrap: 72 markup: yes output-xhtml: no input-xml: no show-warnings: yes numeric-entities: yes quote-marks: yes quote-nbsp: yes quote-ampersand: yes output-xhtml: yes
If you have several HTML files in the same directory and want to use Tidy on all of them simultaneously, you can do the following:
DOS. Use for command, as in:
for %i in (*.html) do tidy %i
UNIX. Use a UNIX shell script, as in:
#!/bin/sh
for i in directory_1 directory_2 directory_3 ... do /absolute_path_to/tidy -config config.txt $i.html done
The following is a CGI-based interface to HTML Tidy. Enter a URI of the HTML document that you wish to convert to XHTML 1.0 in the field below, and press submit:
CYAN is another online interface to HTML Tidy with various input/output options.
HTML-Kit is a freely available program for Windows 9x/NT, designed to help HTML authors to edit, format, validate, preview and publish documents on the Web. It includes a customizable GUI to HTML Tidy for converting documents from HTML to XHTML 1.0. Among other possibilities of viewing, it provides a view with split windows, one with the original markup and the other with the markup after transformation. Errors and suggestions for improving the markup are also reported in a separate window.
An illustration of the output of a document after a HTML to XHTML 1.0 conversion is available. On the documents authored using HTML-Kit, the following icon can be placed as a sign of support:
![]()
There may be times when a need arises to translate a set of XML files to XHTML 1.0, say, for presenting them to HTML 4 user agents. An efficient way of doing that is to use XSLT.
XSLT, the "transformational" part of the Extensible Stylesheet Language (XSL), is a language for transforming XML documents into other XML documents (as well as documents in other formats). Here is an example of using XSLT to create an XHTML 1.0 document from a given XML document.
The XML document is sale1999.xml and the
XSL stylesheet is sales.xsl. The files are processed
using XT, for example, under Windows
9x/NT, as:
C:\path_to\xt sale1999.xml sales.xsl sale1999.htm
where we use the XML document sale1999.xml as input, apply the XSL
stylesheet sales.xsl, and direct the output to an HTML document sale1999.htm.
Many existing visual HTML editors may not be useful in authoring XHTML 1.0 documents as they often insert tags on their own and do not follow the rules that produce syntactically-correct documents. (Even though documents with malformed markup are often tolerated by some browsers at present, that may not always be the case with strictly XHTML-compliant renderers in the future.) Therefore, a judicious choice among visual editors is necessary. One example is HTML-Kit discussed above.
Use of specialized XHTML 1.0 visual editors can be made, as we will see later in this section. General purpose text editors, such as Emacs, could also be useful. For details of editing HTML with Emacs, see the article HTML Editing with Emacs.
There are HTML Compatibility
Guidelines for authors who wish their XHTML 1.0 documents to render on existing HTML
user agents. They suggest the appropriate use of various items (Processing Instructions,
Empty Elements, Element Minimization and Empty Element Content, Embedded Style Sheets and
Scripts, Line Breaks within Attribute Values, Isindex, The lang and xml:lang
Attributes, Fragment Identifiers, Character Encoding, Boolean Attributes, DOM, Using
Ampersands in Attribute Values, CSS).
Amaya is a freely available W3C test-bed
browser/editor that supports XHTML 1.0. The documents, however, must be labeled as text/html
as Amaya does not support XML per se. Amaya gives various options
for output format, including XHTML. Amaya can be particularly useful for authoring
XHTML 1.0 documents with embedded MathML markup, as
its rendering/editor components support both MathML and XHTML 1.0. All one has to do is
include the appropriate XML namespace for MathML in the XHTML 1.0 document.
XML Spy is a commercial XML editor with support for XHTML 1.0, that provides three advanced views of the documents: an Enhanced Grid View for structured editing, a Source View with syntax-coloring for low-level work, and an integrated Browser View. An example illustration of the Enhanced Grid View is available.
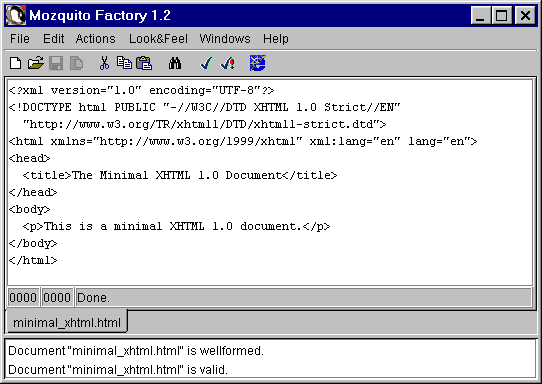
Moqzuito Factory is a
commercial XML editor that is also the first authoring environment especially designed for
the XHTML
family of document types. Among many features, it can check XHTML 1.0 documents for
well-formedness and validity (against any one of the three DTDs
it corresponds to). For example, test results of XHTML 1.0 well-formedness and validity
for the document minxhtml.htm are
shown in the snapshot. On the XHTML 1.0 documents
that validate with the Mozquito Factory, the following icon can be placed:
![]()
Validation is a process whereby documents are verified against the associated DTD, ensuring that the structure, use of elements, and use of attributes are consistent with the definitions in the DTD. Validating an XHTML 1.0 document involves verifying its markup against one of the three associated DTDs. For details on the issue of HTML validation, see the article Stop! Is Your HTML Document Valid?
You can validate XHTML 1.0 by using the online W3C HTML Validation Service which is based on an SGML parser. It comes with various options, such as including Weblint results and displaying the parse tree. It does not support file upload though.
Enter the URI of the document to be validated (without the options though) in the field below, and press submit:
You may display this icon on any page that validates:
![]()
Here is the HTML you could use to add this icon to your Web page:
<a href="http://validator.w3.org/check/referer">
<img src="http://validator.w3.org/images/vxhtml10"
alt="Valid XHTML 1.0!" height="31" width="88" />
</a>
HTML::Validator is a Perl module which can be used to check the validity of HTML, XHTML, SGML, or XML files offline. The validation is performed by nsgmls SGML parser.
There are some additional requirements in XHTML which the XML data content models cannot check, primarily due to the limitations of DTDs. For such cases, an Exclusion Validator for XHTML in XSL is available.
When HTML Compatibility Guidelines are followed, XHTML 1.0 documents can be rendered on HTML 4-compliant browsers. Opera and Amaya have native support for rendering XHTML 1.0.
XHTML : HTML, Alive and Well ... and Better
HTML, as the lingua franca of the Web, has begun to show signs of aging. XHTML has come to the rescue with its family of document types that will provide interoperability on a wide range of new devices.
XHTML 1.0 is the first member of the XHTML family that recasts HTML 4 in XML 1.0. It provides the bridge to authors for entering the structured data world of XML, while still being able to maintain operability with user agents that support HTML 4. The other members of the family are based on a Modularization of XHTML, which provide a means for subsetting and extending XHTML for emerging platforms such as mobile computers and cellular phones. These initiatives include XHTML 1.1 - Module-based XHTML, XHTML Basic, XHTML Events module, and Ruby Annotation.
Transition from HTML to XHTML 1.0 is straightforward if you follow the suggested guidelines for authoring content. This transition has an additional benefit of a smooth passage to XML and use of its applications, while still maintaining backward and future compatibility of the content.
"Welcome to the XML World! Would you please check your (malformed HTML) baggage at the (validator) door? Thank you, and enjoy your (markup) journey."
I am grateful to Hsueh-Ieng Pai and Martin Webb for their critical reading and various useful suggestions. I would also especially like to thank all the users for their feedback since this work first appeared in August 1999.
The following table gives a selected list of options used by HTML Tidy (assuming the input to be an HTML file and output to be an XHTML file); for an entire list, you can refer to the official documentation.
The * | * | ... are Boolean values, the default is indicated in green:
| HTML Tidy Configuration Option | Function |
|---|---|
| markup: yes | no | Determines whether Tidy generates a pretty printed version of the markup. |
| indent: yes | no | auto | Tidy uses this to indent block-level tags. If set to auto Tidy will decide whether or not to indent the content of tags depending on whether or not the content includes a block-level element. |
| output-xml: yes | no | Tidy uses this to generate the pretty printed output writing it as well-formed XML. Any entities not defined in XML 1.0 will be written as numeric entities to allow them to be parsed by an XML parser. The tags and attributes will be in the case used in the input document, regardless of other options. |
| add-xml-pi: yes | no | Tidy uses this to add the XML processing instruction when outputting XML or XHTML. |
| output-xhtml: yes | no | Tidy uses this to generate the pretty printed output writing it as XHTML. This option causes Tidy to set the doctype and default namespace as appropriate to XHTML. If a doctype or namespace is given they will checked for consistency with the content of the document. In the case of an inconsistency, the corrected values will appear in the output. For XHTML, entities can be written as named or numeric entities according to the value of the "numeric-entities" property. The tags and attributes will be output in the case used in the input document, regardless of other options. |
| doctype: omit | auto | strict | loose | <fpi> | This property controls the doctype declaration generated by
Tidy.
|
| numeric-entities: yes | no | Causes entities other than the basic XML 1.0 named entities to be written in the numeric rather than the named entity form. |
| quote-ampersand: yes | no | This causes "&" characters to be written out as &. |
| logical-emphasis: yes | no | This causes Tidy to replace any occurrence of <i>
by <em> and any occurrence of <b> by <strong>.
In both cases, the attributes are preserved unchanged. |
| enclose-text: yes | no | This causes Tidy to enclose any text it finds in the body
element within a <p> tag. This can be useful when you want to use an
existing HTML file with a style sheet. |
| write-back: yes | no | Tidy uses this to write back the tidied markup to the same file it read from. |
| error-file: filename | Writes errors and warnings to the named file rather than to stderr. |
| show-warnings: yes | no | This can be useful when a few errors are hidden in a long list of warnings. If set to no, warnings are suppressed. |
The State of MathML : Mathematically Speaking (and Stuttering)
XML Namespaces : Universal Identification in XML Markup
{kind=link}
{kind=link}
{kind=link}
{kind=link}