Perspectives of XML in E-Commerce
XML Conformance : The Burden of Proof
XML and CSS : Structured Markup with Display Semantics
XML Namespaces : Universal Identification in XML Markup
The Emperor has New Clothes : HTML Recast as an XML Application
You are here: irt.org | Articles | Extensible Markup Language (XML) | XML Entities and their Applications [ previous next ]
Published on: Sunday 21st May 2000 By: Pankaj Kamthan
XML provides both a logical structure and a physical structure to a document. The logical structure tells what elements are to be included in a document and in what order. The physical structure governs the content in a document in form of storage units called entities. In general, entities allow you to assign a name to some content, and use that name to refer to that content.
Entities have several uses. For example, they allow you to create "macros" for content, which can be referred to in the document simply by referring to its name. For example special characters or images, can be included in form of entities. This results in reusability of same content without the need of unnecessary repetition of them in the document. It also leads to efficient management and future modifications as now they can reside in a central location.
The goal of this article is to discuss different aspects of XML entities, including some possible applications and scenarios of use. We assume that the reader is familiar with the basics of XML and DTD syntax.
There are several reasons that have motivated the introduction of entities:
In the foregoing, examples are presented that elaborate these points.
This section provides the basic characteristics that are inherent in all entities as well as relevant definitions.
name. Entities
must have a unique name within their namespace. General and parameter entities
occupy different namespaces; a parameter entity and a general entity with the same
name are two distinct entities. In case of a parsed entity, the name identifies
the entity in an entity reference. In
the case of an unparsed entity, the name identifies the entity in the value of an ENTITY
or ENTITIES attribute. The details are discussed in the section Entity Declarations and References and Entity Attributes..ent
is commonly used for external general entities and .mod commonly used for
external parameter entities. The notion of entities has apparent similaries to various concepts found in modern object-oriented system programming languages, such as, C++ and Java (which is not surprising considering that XML reflects an inclination towards object serialization):
#include in C++ or import
in Java, idea of preprocessing as in Server-Side Includes (SSIs) and Active Server Pages
(ASP).Entities can be categorized as follows: Internal vs. External, General vs. Parameter, Parsed vs. Unparsed. Among the possible eight (23) combinations, only the following five different entity categories are considered legal: internal general parsed, internal parameter parsed, external general parsed, external parameter parsed, and external general unparsed. Some conclusions that can be drawn from this classification are: any entity appearing in the internal subset of a DTD is always parsed, parameter entities are always parsed, and there is only one type of entity that is unparsed. Furthermore, parameter entities can appear only in the internal or external subset of a DTD, where treatment in both cases is identical.
Thus, with appropriate references to whether the entity is parsed or unparsed, we can effectively reduce our categories of discussion to the following :
When concepts apply to an overlapping category, we will use terms that apply to all without any loss of generality and any potential of ambiguity. For example, by internal entities we mean both internal general and internal parameter entities, by general entities we mean both internal general and external general entities and by parameter entites we mean both internal parameter and external parameter entities.
Internal entities function as shortcuts or macros. With internal entities, you can associate an essentially arbitrary piece of text (which may have other markup, including references to other entities) with a name. The text that is inserted by an entity reference is called the replacement text. The replacement text of an internal entity can contain markup (elements, attributes, processing instructions, other entity references, and so on), but the content must be balanced (any element that is started in an entity must end in the same entity) and recursive entity references are not allowed. There is no separate physical storage object, and the content of the entity is given in the declaration. Internal entities can include references to other internal entities, but it is an error for them to be recursive.
Internal entites are important from a processing point of view. Every conforming XML processor is required to do internal entity processing, if the entities are declared in the internal DTD subset.
There are five predefined internal entities in XML, as shown in Table 1. The <
and & characters in the declarations of "lt" and
"amp" are doubly escaped to meet the requirement that entity
replacement be well-formed.
| Entity | Entity Name | Replacement Text |
| The left angle bracket (<) | lt |
&#60; |
| The right angle bracket (>) | gt |
> |
| The ampersand (&) | amp |
&#38; |
| The single quote or apostrophe (') | apos |
' |
| The double quote (") | quot |
" |
Table 1. Predefined Entities.
All XML processors are required to recognize these entities whether they are declared or not. For interoperability, valid XML documents should declare these entities, prior to use. If the entities in question are declared, they must be declared as internal entities whose replacement text is the single character being escaped or a character reference to that character. For example, the fragment
<?xml version="1.0" encoding="UTF-8"?>
<algebra>
"{x: 0 &#60; x &#38; x > 1} has
'no solution' in the set of real numbers."
</algebra>when processed yields:
"{x: 0 < x & x > 1} has 'no solution' in the set of real numbers."Character reference refers to specific characters in the ISO/IEC 10646 (now part of Unicode) character set. They allow you to include the specified Unicode standard character directly into your document, even if they are unavailable directly on your keyboard or are not portable across applications and operating systems. Character references are also very useful for dealing with multilingual texts.
Character references are numeric and can be used without any special declaration. If
the character reference begins just with "&#", the digits up to
the terminating ; provide a decimal representation of the Unicode
character number. If the character reference begins with "&#x",
the digits and letters up to the terminating ; provide a hexadecimal
representation of the Unicode character number.
REMARKS
Character references are similar in appearance to entity references but differ from
other entity references in processing. They are expanded immediately when recognized by
the parser. As an example, using '"' is identical to '"'
and, therefore, a character reference can not be used in an attribute value to escape the
quotation characters.
Numeric character references can also be used to escape the left angle bracket, and
other delimiters for which there exists a set of predefined
entities. However, in general, using names is better than using character references
since names are more (humanly) "intuitive." Thus, for example, to encode <, <
is preferred over <.
The uses of internal entities depend on the two possible views of internal entities: as macros (from a programming viewpoint) and as "boilerplates" (from a publishing viewpoint). They are useful in many situations:
External entities are all those that are not internal. They can consist of more than a single element, such as, an external entity consisting of some character data with embedded inline markup. The tags in an external entity must be well balanced within the entity (you can not start a tag in an entity and end it in your document or in another entity). External entities can reference internal or other external entities, but must not contain a recursive reference to itself, either directly or indirectly. The same external entity can be referred several times in a single document (if the document is to be validated, however, ID attributes should not be used in the external entity). It is legal to have several external entities that all refer to the same external file. There are no additional restrictions placed on the character encodings used by external entities. In particular, external entities with different encodings can be used in the same document.
External entities, like internal entities, have names and are referenced in the same manner, although they are declared differently, which serves as one way of recognizing them.
The following are some primary uses of external general entities:
Parameter entities are only available within the internal and external subsets of the DTD. They can be either internal or external, but they can not refer to non-XML data.
Parameter entities are most frequently used to customize and extend DTDs. Definition of variables for use inside the DTD (parameter entities). This is used to modularize a DTD for reuse and ease of maintenance.
The document entity serves as the root of the entity tree and a starting-point for an XML processor, and may contain the whole document. The first design goal of XML says that "XML shall be straightforwardly usable over the Internet." In a networking environment, it is typically expensive to serve documents split in multiple modules. The document entity is all that a non-validating XML processor is required to read. The advantage of this is that documents can be authored in multiple independent modules, composed together, and delivered as a single component - the document entity.
If the XML document is in a file, the document entity is that file. If the XML document is being accessed via a URL, then the stream of bytes that obtained by calling a function is the document entity.
The document entity is special in many ways. The differences between the document entity and any other external parsed entity are:
Entities declarations carry the following general characteristics:
ENTITY declaration.
The exact form of the declaration distinguishes between internal, external, and parameter
entities.Entities references carry the following general characteristics:
&), percent sign (%) and
semicolon (;) as delimiters. This serves as one way of identifying them in
the documents they appear. ENTITY or ENTITIES
attributes, and conversely, unparsed entities can be referred to only in attribute values declared to be of type
ENTITY or ENTITIES. All internal entities must be declared in the internal or external DTD subsets. Entity references should follow their declaration in the source. At the time of being parsed, an entity reference at a given point in an XML document instance triggers the substitution of its contents at that point. Entity definitions can themselves refer to other internal and previously defined entities. You create internal entities with entity declarations in the internal subset or the DTD.
It is an error to insert an entity reference to an unparsed entity directly into the
flow of an XML document. Unparsed entities can only be used as attribute values on
elements with ENTITY
attributes.
Internal general entity declarations, which can occur only in the DTD, have the following form:
<!ENTITY entityname "replacement text">
You can use either double or single quotes to delimit the replacement text. For example, if your document frequently refers to, say, "World Wide Web Corporation," you could declare it as an entity:
<!ENTITY wwwc "World Wide Web Corporation">
You can then insert it as needed in your document with the entity reference &wwwc;, which saves typing it out each time.
Internal general entity references, can occur both in the DTD and the document instance. They consist of an ampersand (&), followed by the name of the entity, followed by a semicolon (;). They are not expanded in the DTD and are of the form
&entityname;
For example, to refer to "John Wiley & Sons" in a document by &jws;, we can have the following entity:
<!ENTITY jws "John Wiley & Sons">
If an internal entity will be used in several documents, it is preferable to add that to an external file (or DTD) instead of declaring them in the internal DTD subset. This has the following advantages:
An entity declaration can include another entity reference within it as long as the reference is not, either directly or indirectly, recursive. Therefore, recursive entity declarations such as the following should not be used:
<!ENTITY endless "&loop;"> <!ENTITY loop "&endless;">
CONSTRUCTION OF INTERNAL ENTITY REPLACEMENT TEXT
The construction of internal entity replacement text discusses the treatment of internal entities, general as well as parameter, and distinguishes two forms of the entity's value: the literal entity value and the replacement text.
entity value. The literal
entity value as given in an internal entity declaration may contain character,
parameter-entity, and general-entity references. Such references must be contained
entirely within the literal entity value. Example 1. This example shows that a literal entity value and the replacement text can be different. It also shows that the replacement text can be different from what may eventually appear in the document's content or an attribute value once a general entity is referenced and expanded.
Consider the declarations:
<!ENTITY % company "Yoyodyne, Inc."> <!ENTITY legal "All Rights Reserved."> <!ENTITY signature "© 1999 %company;. &legal;">
The literal entity value for the entity "signature" is:
© 1999 %company;. &legal;
The replacement text for the entity "signature" is:
� 1999 Yoyodyne, Inc. &legal;
The entity "signature" once referenced and expanded in the
document's content or an attribute value is:
� 1999 Yoyodyne, Inc. All Rights Reserved.
External entity declarations come in two forms depending on whether the entity is in an XML format or in a non-XML format. External general entities are referenced in the same manner as the internal general entities.
There are two cases here.
I. The External Identifier contains a System Identifier.
When the external entity contains some XML format, the declaration can have the following form:
<!ENTITY entityname SYSTEM "system-identifier">
The external identifier is preceded by the keyword SYSTEM and followed by a system
literal. This is also known as the system
identifier which is a system
literal in the form of a URI and is used to retrieve the entity. Often the URI
can be a simple filename.
Example 2. XML documents can be of arbitrary
complexity and size, and delivery performance can become as issue. External entity
declarations can be useful for large document management by dividing them into components,
which can later be included in the parent document via entity references. Given such a
document, filename.xml, you can divide it into logical components (say,
sections) and store them in separate files (say, section_1.xml, ..., section_m.xml).
The following defines an external entity that incorporates these sections into your
document can be declared like so:
<!ENTITY section1 SYSTEM "path/to/section_1.xml"> ... <!ENTITY sectionm SYSTEM "path/to/section_m.xml">
Then, the "parent" document filename.xml (which is actually the
document entity) can consist of just the references to the entities:
<?xml version="1.0" encoding="UTF-8"?> <document> §ion1; ... §ionm; </document>
Thus, we see that entire documents can be created using entities.
II. The External Identifier contains Public Identifier and a System Identifier.
A public identifier is a name that is intended to be semantically interoperable across different computer environments. It is an ISO standard (ISO/IEC:9070, 1991). In addition to a system identifier, an external identifier may include a public identifier. The external identifier can be preceded by the keyword PUBLIC, which must then also contain a public identifier literal followed by a system literal in form of a URI.
When the external entity contains some XML format, the declaration can thus also have the following form:
<!ENTITY entityname PUBLIC "public-identifier" SYSTEM "system-identifier">
A public identifier can be useful when working with an entity that is publicly available. The XML processor can check the public identifier against a list of resources to which it is connected and determine whether or not it needs to get a new copy of the entity. However, until such public information storage mechanisms become more widely available and canonical, the system identifier will be more commonly used. Thus, XML allows you to use public identifiers, but you still have to provide a system identifier (URI) for each external entity. An XML processor attempting to retrieve the entity's content may use the public identifier to try to generate an alternative URI. If the processor is unable to do so, it must use the URI specified in the system literal.
The following declaration makes use of the XHTML 1.0 public identifier:
<!ENTITY PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" SYSTEM "http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">
External entities that refer to non-XML data files must declare that data they contain is not in XML. This is accomplished by using notation declarations.
A notation is a name, with an associated external
identifier, which can be applied to unparsed entities (and also, when used in a NOTATION
attribute, to the content of elements). It identifies by name the format of unparsed entities, the format of
elements with a notation attribute, and the application to which a processing instruction is addressed. The
basic idea is that the notation (name and an external identifier) should be helpful in
handling the data (unparsed entities) to which it is attached. A notation declaration thus
consists of a name for the notation, and an external identifier that allows the XML
processor to locate an application to process data that is flagged to be in the given
notation.
The notation declaration has the form:
<!NOTATION entityname PUBLIC "public-identifier" notation> <!NOTATION entityname SYSTEM "system-identifier" notation>
If both public and system identifier are provided, the public identifier should come first, and the system identifier should not be preceded by the word SYSTEM. Entities using a notation are unparsed entities.
An example is:
<!NOTATION GIF87A SYSTEM "C:\Program Files\gifviewer.exe" GIF>
This information is passed by the XML processor to the application, which may use it however it wishes to. Note that XML processors provide applications with the name and external identifier(s) of any notation declared and referred to. They may additionally help the application process the data described in the notation by resolving the external identifier into the system identifier, file name, or other information. However, it is not within the scope of an XML processor to deal with the unparsed entities.
There are specific attributes in the DTD syntax to express external general entities with non-XML data. See the section on Entity Attributes for more details.
Parameter entity declarations, which can occur only in the DTD, are identified
by a % preceding the entity name. They are of the form:
<!ENTITY % parameterentityname1 "replacement text"> <!ENTITY % parameterentityname2 SYSTEM "URI">
Note the space following the % in the declaration. The declaration of a
parameter entity must precede any reference to it.
Parameter entity references, can occur only in the DTD part of the document instance. They consist of a percent symbol (%), followed by the name of the entity, followed by a semicolon (;). They are of the form
%parameterentityname;
The following declaration defines the parameter entity subdtd, a part of a DTD can be referenced from inside the internal or external DTD subsets,
<!ENTITY % subdtd SYSTEM "http://path/to/filename.dtd">
Example 3. This example shows a section (which has been edited here for convenience) of the SVG DTD that uses parameter entities in the definition of the circle element:
<!-- Allow at most one of description and title, supplied in any order. -->
<!ENTITY % descTitle "((desc,title?)|(title,desc?)?)">
<!-- Allow extending the DTD with internal subset for graphics elements. -->
<!ENTITY % geExt "">
<!-- Use of entities in the circle element. -->
<!ENTITY % circleExt "">
<!ELEMENT circle (%descTitle;,(animate|set|animateMotion|animateColor|animateTransform
%geExt;%circleExt;)*)
>REMARKS
foo. Then, if the string %foo; appears
somewhere in the document outside of the DTD, it is not an error. It is just the string %foo;.
Conditional sections are a mechanism for parameterizing the DTD. Note, however, that you cannot use conditional sections in the internal subset of XML documents.
Conditional Sections are portions of the external DTD subset which are included in, or excluded from, the logical structure of the DTD based on the keyword which governs them. Like the internal and external DTD subsets, a conditional section may contain one or more complete declarations, comments, processing instructions, or nested conditional sections, intermingled with white space.
A markup declaration, which is only allowed in the conditional section, is an element type declaration, an attribute-list declaration, an entity declaration, or a notation declaration. These declarations may be contained in whole or in part within parameter entities. They are introduced by the sequence:
<![KEYWORD[ ... ]]>.
The most common KEYWORD's are:
INCLUDE. INCLUDE indicates that the contents
of the conditional section are part of the DTD.IGNORE. IGNORE indicates that the contents of
the conditional section are not logically part of the DTD and text in section should be
ignored (it completely disappears from the parsed document). Note that for reliable
parsing, the contents of even ignored conditional sections must be read in order to detect
nested conditional sections and ensure that the end of the outermost (ignored) conditional
section is properly detected. CDATA. CDATA indicates that the contents of
the section should be ignored except for the closing characters ]]>. (Note
that CDATA sections are allowed in an XML document, but the keyword cannot be a parameter
entity.)If a conditional section with a keyword of INCLUDE occurs within a larger
conditional section with a keyword of IGNORE, both the outer and the inner
conditional sections are ignored. If the keyword of the conditional section is a parameter
entity reference, the parameter entity is replaced by its content before the processor
decides whether to include or ignore the conditional section.
Example 4.The following example illustrates
the use of INCLUDE and IGNORE. A company can use these
constructs for presenting a document (brochure) for internal (private) and external
(public) use.
<!ENTITY % private "INCLUDE"> <!ENTITY % public "IGNORE"> <![%private;[ <!ELEMENT brochure (comments*, cost, title, body)> ]]> <![%public;[ <!ELEMENT brochure (title, body)> ]]>
References to an unparsed entity can occur only in attribute values that were declared to be of types ENTITY and ENTITIES. As with attribute declarations, the first occurrence of an entity declaration takes precedence. This allows declarations to be made in the DTD's internal subset which is read prior to the external subset, thus overriding possible definitions for the same entity name in the external subset.
For handling nonparsable data, we must specify the NDATA keyword followed by the name of a notation. This allows the data to be passed to and handled by an application capable of interpreting that notation.
A common use of unparsed entities in entity attributes is in XML elements that incorporate graphics into a document.
Example 5. This example illustrates the use of the ENTITY attribute:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE document [
<!ELEMENT document (graphics)+>
<!ELEMENT graphics EMPTY>
<!ATTLIST graphics image ENTITY #REQUIRED
alternative CDATA #IMPLIED>
<!NOTATION PNG SYSTEM "/usr/local/bin/PNGViewer">
<!ENTITY logo SYSTEM "logo.png" NDATA PNG>
<!ENTITY wwwc "World Wide Web Corporation">
]>
<document>
<!-- The following image is the World Wide Web Corporation logo. -->
<graphics image="logo" alternative="&wwwc; Logo"/>
</document>In this example, the image is an ENTITY attribute and contains only the name (logo) of
the unparsed entity (logo.png) whereas alternative is a parsed entity and
contains the reference (&wwwc;) to the internal general entity (wwwc).
Example 6. There may be data that may not
render itself suitable for expression in XML syntax or there may be some legacy data that
is considered unfit for a transition to XML for one reason or the other. Such can be the
case for data in binary formats. For example, for photographs, JFIF (more commonly known
as JPEG) is the preferred format of use over Portable Network Graphics (PNG) or Scalable
Vector Graphics (SVG). External entities in such cases can be used for backward
compatibility. As an example, suppose we have an image, ottawa.jpg, of the
City of Ottawa, Canada. Then, the following declaration declares the entity ottawa
as a JPEG image:
<!ENTITY ottawa SYSTEM "ottawa.jpg" NDATA JPG>
Entities declared this way cannot be inserted directly into the document, and conversely, entities declared without a notation as the value of an entity attribute cannot be used. Such entities must be used as entity attributes to elements:
<graphics image="ottawa"></graphics>
There are differences between entity attributes and entity references in attribute values, as discussed in the next section.
Unparsed entities are allowed in entity attributes, where parsed entities are
forbidden. Unparsed entities may be referred to only in attribute values declared to be of type
ENTITY or ENTITIES. An ENTITY attribute can only
contain the name of an unparsed entity. In particular, it contains the name of the entity,
and not a reference to the entity.
In the next example, the attributes point to external data in the form of unparsed entities:
<!-- Attribute b points to a single unparsed entity --> <!ATTLIST a b ENTITY #IMPLIED> <!-- Attribute c points to multiple unparsed entities --> <!ATTLIST a c ENTITIES #IMPLIED>
Parsed entities are allowed in the body of the document, whereas unparsed entities are forbidden. References to internal entities in attribute values are allowed, external entity references in attribute values are not. An entity reference must not contain the name of an unparsed entity. The following:
<?xml version="1.0" encoding="ISO-8859-1"?> <!DOCTYPE document [ <!ENTITY logo SYSTEM "logo.png" NDATA PNG> ]> <document> <!-- The following image is the World Wide Web Corporation logo. --> .. <p>The company logo: &logo;</p> </document>
is not allowed because an unparsed entity could be binary (as above) and embedding it in midst of some text will be indecipherable (atleast to humans).
There are sets of entities which are frequently used by large communities of
geographically dispersed people with common goals. Such is the case, for example, among
users of mathematical notation or natural language characters. This raises the possibility
of potential incompatible usage of same symbols under different names, or even name
collisions. For example, one user may use &diff; and the other may use
&difference; to mean the difference of two sets (say, A - B) in a Set
Theory context, whereas a third user may use &diff; to denote the differential sign
(say, dx) used in Calculus. To avoid this situation, the process of
associating names with entities needs to be formalized and standardized. The two major
bodies that carry out this standardization process are ISO
and Unicode.
This section summarizes the entity expansion and the (expected) treatment of entities and references by an XML processor. The details are given in Section 4.4 and Appendix D of the XML Specification.
An XML processor as described in
the treatment of entities and references
inserts the replacement text of a parsed entity into the document wherever a reference to
that entity occurs. There is a table
that summarizes the contexts in which character references, entity references, and
invocations of unparsed entities might appear and the required behaviour of an XML processor in each case. This
includes what is and what is not
recognized, when is an entity included,
what should the processor do (include/not include) when it comes across external parsed entities or parameter entities, what to do when an entity reference appears in an attribute
value, or a parameter entity reference appears in a literal entity value, what to do when
the name of an unparsed entity
appears as a token in the value of an attribute of declared type ENTITY or ENTITIES,
what to do when a general entity reference appears in the EntityValue in an entity
declaration, and what type of references are not allowed (forbidden). Some highlights and useful
consequences are:
% character (which when present in the DTD, would be treated as a
parameter entity reference), has no special significance outside the DTD and is not
recognized. ENTITY or ENTITIES,
a validating processor must inform the application of the system and public (if any) identifiers for both the
entity and its associated notation.
What the application does with it, is the responsibility of the application, not the
processor. EntityValue
or AttValue), a
reference to an external entity in an attribute value are not allowed.Different processors may differ in their implementation of entities. For example, in Microsoft XML Parser
(MSXML) the entity declaration <!ENTITY lt "<"> is
considered invalid since it can not be legally expanded.
A complete XML authoring software will usually have a support for entity expansion. A standalone entity expander entity.exe is also available which simply expands the entities in an XML file.
Character references are expanded immediately. General entity references that appear in
the entity value
of an entity declaration are not expanded (bypassed
and left as is) by an XML processor until the entity being declared is referenced. Thus,
general entities do not have to be declared before being used and the order of general
entity declarations is unimportant. (However, the declaration of a general entity must
precede any reference to it which appears in a default value in an attribute-list (ATTLIST)
declaration.) For example, the following set of declarations:
<!ENTITY wwwc "&www; Corporation"> <!ENTITY www "World Wide Web">
are legal in the internal subset because the entity reference "&www;"
is expanded after "&wwwc;" is expanded.
Example 7. The following is an example which illustrates a sequence of complex interactions in entity recognition, processing and expansion:
<?xml version="1.0" encoding="UTF-8"?>
<!DOCTYPE document [
<!ELEMENT document (quote)+>
<!ELEMENT quote (#PCDATA)>
<!ENTITY r 'Rumple'>
<!ENTITY s 'stilskin'>
<!ENTITY % y '<!ENTITY x "&r;&s;">'>
%y;
]>
<document>
<quote>
"My name is &x;, but you can call me r12n."
</quote>
</document>which upon parsing (with, for example, XML4C) should yield:
<document> <quote> "My name is Rumplestilskin, but you can call me r12n." </quote> </document>
An XML authoring software that has support for DTDs will typically provide features for entity well-formedness and validation. XML Spy is a commercial XML editor with such support. For Example 5, we have the Enhanced Grid View, the Source View, and the validation test, illustrated in the screenshots below.
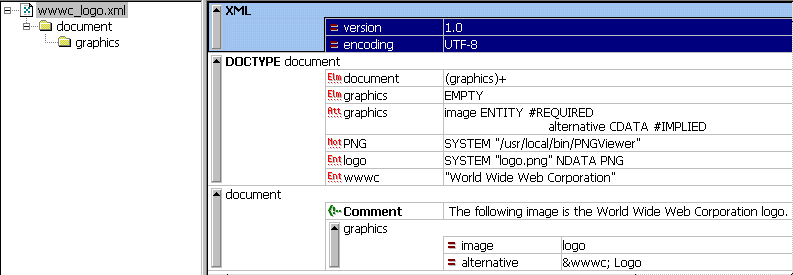 |
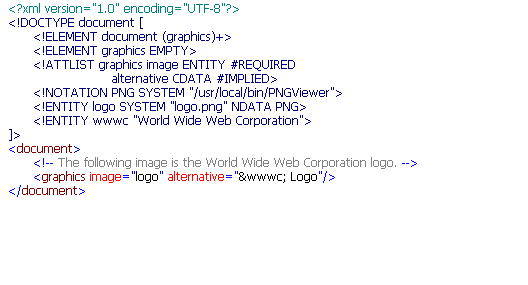 |
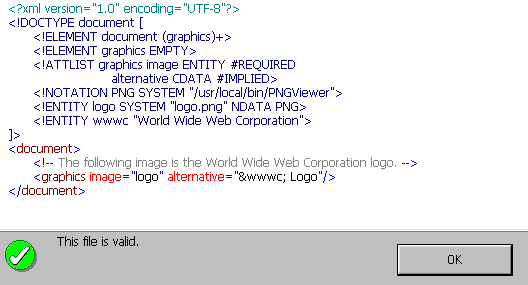 |
| Enhanced Grid View | Source View | Validation Test |
As seen previously, one of the options for declaring entities is via a URI, and when this is the case, the XML processor is in some sense doing a client-side includes in an XML document. It is possible to do this dynamically by extending an XML parser that implements the XML DOM, to change the values of entities after it has parsed the DTD, but before it begins parsing the document. (It is not possible to do that by just walking the DOM and looking for entity reference nodes in a DOM, since certain entity references are resolved at parse time and adjacent text nodes are normalized.) This can be useful if the entities are available publicly but copyrighted, and explicit distribution, except from the originating source, is not allowed.
It may be desirable to view or edit one or more of the entities or parts of entities while having no interest, need, or ability to view or edit the entire document. The XML Fragment Interchange defines a way to send only such fragments of an XML document.
Since external entities in different documents can refer to the same files on your file system, they provide an opportunity for reuse strategy. DTDs which make a large-scale [re]use of entities require an entity management system, which XML, by itself, does not provide.
OmniMark is a SGML/XML content mangement system which provides a variety of support for entities. In the absence of an entity management system (which are often commercial and can be expensive), certain entity-related tasks can be carried out via scripts or style sheets. If you used to declare entities within XML document files, there is a Perl script that will move them to external DTD files. Using a DSSSL script, MathML entities were extracted from unicode.xml to yield the MathML DTD.
SGML entities differ from XML entities in various significant ways, particularly in terms of flexibility. For example, SGML parameter entity declarations are not restricted only to the DTD. The transition of SGML entity-base to XML then becomes an issue. There has been effort to convert HTML entities (which are SGML entities) in an XML format. Recently, HTML entities have been converted to XML format to be used in XHTML 1.0. Similar efforts have been carried out for DocBook.
The use of entities is already pervasive in HTML. There are several symbols commonly used, such as, in legal contexts (copyright, registered, trademark), financial contexts (currencies), and internationalization contexts (Arabic, Cyrillic, Greek).
Entities can make entering and managing data easier in various respects:
These possibilities have been illustrated at an elementary level in Example 2 and Example 4.
The entity base for basic mathematical notation has been strong in HTML (and now XHTML) since HTML 3.2 (though support for rendering in widely-used browsers has always been lacking).
Example 8. Let A and B be two sets. The number of elements in A union B is equal to the number of elements in A plus the the number of elements in B minus the number of elements in A intersection B can be expressed as:
n(A ∪ B) = n(A) + n(B) − n(A ∩ B).
More complex constructions are possible. We have extracted useful mathematically-oriented entities from XHTML 1.0 and made them available. It could be used as follows:
<!ENTITY % HTMLmath SYSTEM "xhtml-math.ent"> %HTMLmath;
Notation is at the heart of mathematical representation and evolution of mathematics as a subject. As a result, mathematics makes use of a very large collection of symbols. It is difficult to write mathematics fluently if these characters are not available for use in coding. Furthermore, it is difficult to read mathematics if glyphs are not available for presentation on specific display devices.
MathML has an extensive support entities and characters, which has taken on directly specification of part of the full mechanism of proceeding from notation to final presentation, and is collaborating with organizations (ISO, The STIX Project, Elsevier Science, Wolfram Research) undertaking specification of the rest.
TtH, software for translating [LA]TEX to HTML and its successor, TtM, software for translating [LA]TEX to MathML make a wide use of symbols for rendering mathematical notation.
Parameter entities are often used in large-scale DTDs for compactness (and thus time and space efficiency) and for ease of maintenance. See the section on Parameter Entities. You can not use character or general entities in the DTD, you have to use parameter entities. This is a because DTDs use a different syntax from that of documents. Parameter entities are not needed for schemas based on XML syntax (such XML Schema).
One can extend the capabilities of a DTD using entities in two different ways: (1) by adding an entity to (the internal DTD subset of) an XML document or, (2) by adding an entity to the external DTD subset.
Example 9. This example shows how you can add a "nonstandard" entity to a XHTML document.
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Strict//EN" "http://www.w3.org/TR/xhtml1/DTD/xhtml1-strict.dtd" [ <!ENTITY r "Rumplestilskin"> ]> <html xmlns="http://www.w3.org/1999/xhtml" xml:lang="en" lang="en"> <head><title>My Name is Not Bond</title></head> <body> "My name is &r;, but you can call me r12n." </body> </html>
DocBook is a widely-used DTD in publishing and makes sophisticated use of parameter entities for customization.
Let *ML be an XML vocabulary. In order to combine *ML and XHTML into a single DTD, an author would:
An example of a complex module that can be added to XHTML is the MathML DTD.
Example 10. Extension of XHTML 1.0 Transitional DTD by the MathML 1.0 DTD.
<!-- This assumes that the DTD's are available locally. --> <!ENTITY % xhtml SYSTEM "xhtml1-transitional.dtd"> <!ENTITY % mathml SYSTEM "mathml1.dtd"> <!-- We will use MathML entities. Declare XHTML entities empty (to override them). --> <!ENTITY % HTMLlat1 ""> <!ENTITY % HTMLsymbol ""> <!ENTITY % HTMLspecial ""> <!-- Add MathML to HTML Content Model at an appropriate place. --> <!ENTITY % misc "ins | del | script | noscript | mathml:math"> <!-- Load XHTML and MathML. --> %xhtml; %mathml;
A formal framework towards modularization of XHTML has been initiated. Using this, XHTML can be extended by building XHTML modules by adding a module to XHTML (or to a subset of XHTML). The module being added is incorporated in the DTD by reference rather than explicitly including the new definitions in the DTD. XHTML 1.1 has a single DTD (as opposed to XHTML 1.0 which has three DTD's). An example of the extension of XHTML 1.1 DTD by the MathML 1.0 DTD has been provided.
REMARKS
One should not increase, beyond what is necessary, the number of entities required to explain anything.
- William of Ockham (1285-1349)
Inspite of the fact that entities have various advantages and use, there are a few caveats:
Entities are a fundamental concept in XML. Use of entities offers a number of benefits such as providing the possibility to define commonly used text in a single location for reuse, and to divide mololithic documents into manageable modules. When used appropriately, they can be the underlying foundation of large-scale document production and management in both internal (intranet) and external (Internet) environment with long-term potential benefits.
This work has benefited from the insightful annotations by Tim Bray, co-editor of the XML 1.0 Specification, and without which, it would have been incomplete. I would also like to thank Martin Webb who made several useful editorial suggestions.
Perspectives of XML in E-Commerce
XML Conformance : The Burden of Proof
XML and CSS : Structured Markup with Display Semantics
XML Namespaces : Universal Identification in XML Markup
The Emperor has New Clothes : HTML Recast as an XML Application
{kind=link}
{kind=link}
{kind=link}